Statistiques bi variées - Regression
1 Données d’exemple
On travaille à présent sur un croisement de deux agrégats financiers. On récupère la donnée à partir de l’interface les données de l’ofgl plutôt que celle de la cartographie.
Enoncer les hypothèses possibles de la comparaison, attention variable explicative (X) et à expliquer (Y)
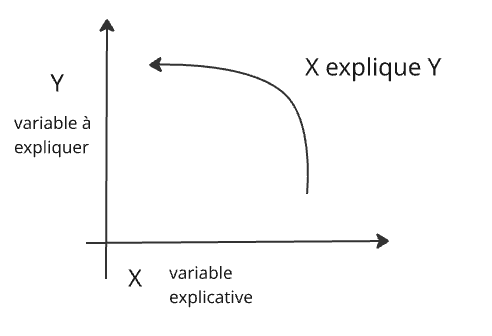
Pour le cours, l’hypothèse est que la non maîtrise des frais de personnel (X) amène l’augmentation des impôts locaux (Y) sur le 93 (budgets).
Pour mémoire, l’hypothèse nulle (H0) est l’absence de relation entre impôts locaux et frais de personnel.
2 Nuage de points
2.1 Quel agregat choisir ?
Quelle variable est liée aux frais de personnel (X) ?
data <- read.csv("data/data93_2024.csv", row.names = 1,dec = ",")
noms <- names(table(data$Agrégat))
png("img/agregatChoix.png", width = 2400, height = 2400, res = 100)
par(mfrow = c(8,8))
for (n in noms){
tmp <- data [data$Agrégat==n,]
jointure <- merge(tmp, personnel, by = "Nom.2024.Commune")
plot(jointure$Montant.en...par.habitant.y,jointure$Montant.en...par.habitant.x, xlab = "Frais de personnel", ylab = n, col="coral", pch = 16)
}
dev.off()## png
## 2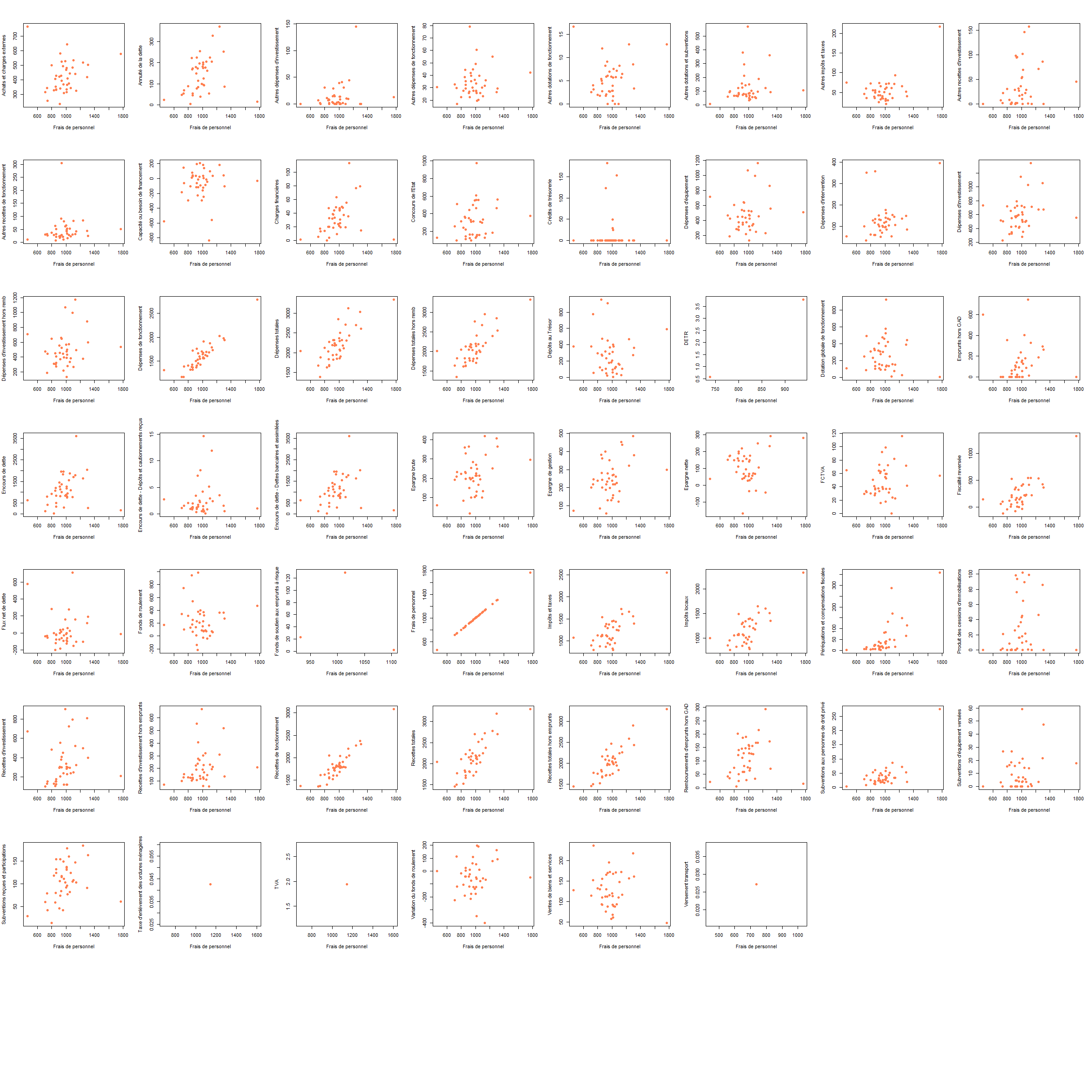
Attention, encore une fois, variable explicative et expliquée.
2.2 Savoirs faire tableur
Mise en forme du tableau
- tcd le fameux tableau croisé dynamique (données table dynamique dans Calc)
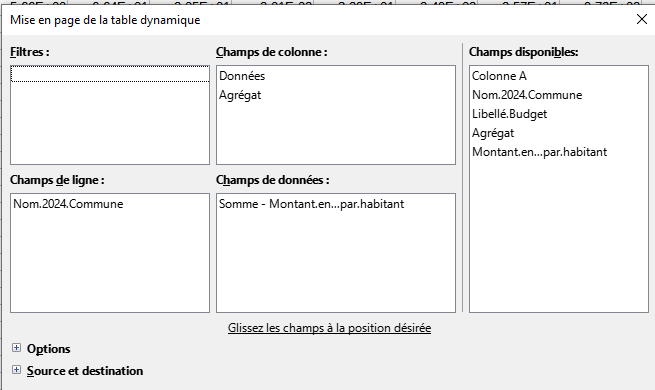
- sélectionner uniquement les 2 colonnes de données (filtre sur tcd)
- types de diagramme ; xy - dispersion
Attention, le diagramme ne s’affiche pas correctement à partir du tcd, il faut faire une copie des deux variables.
2.3 Simplification des chiffres
2.3.1 Redéfinition des bornes
Retour sur les distributions pour enlever les valeurs aberrantes
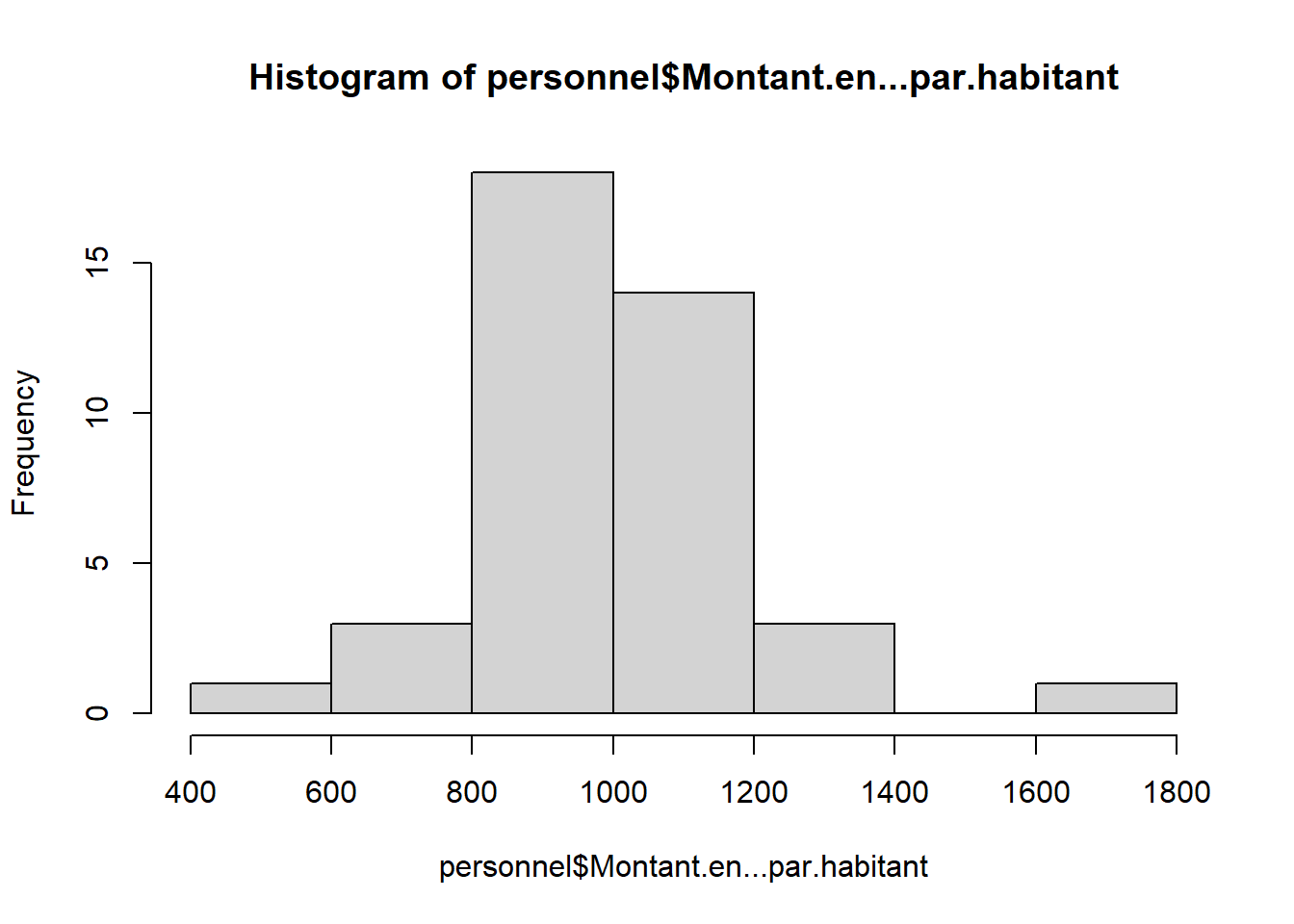
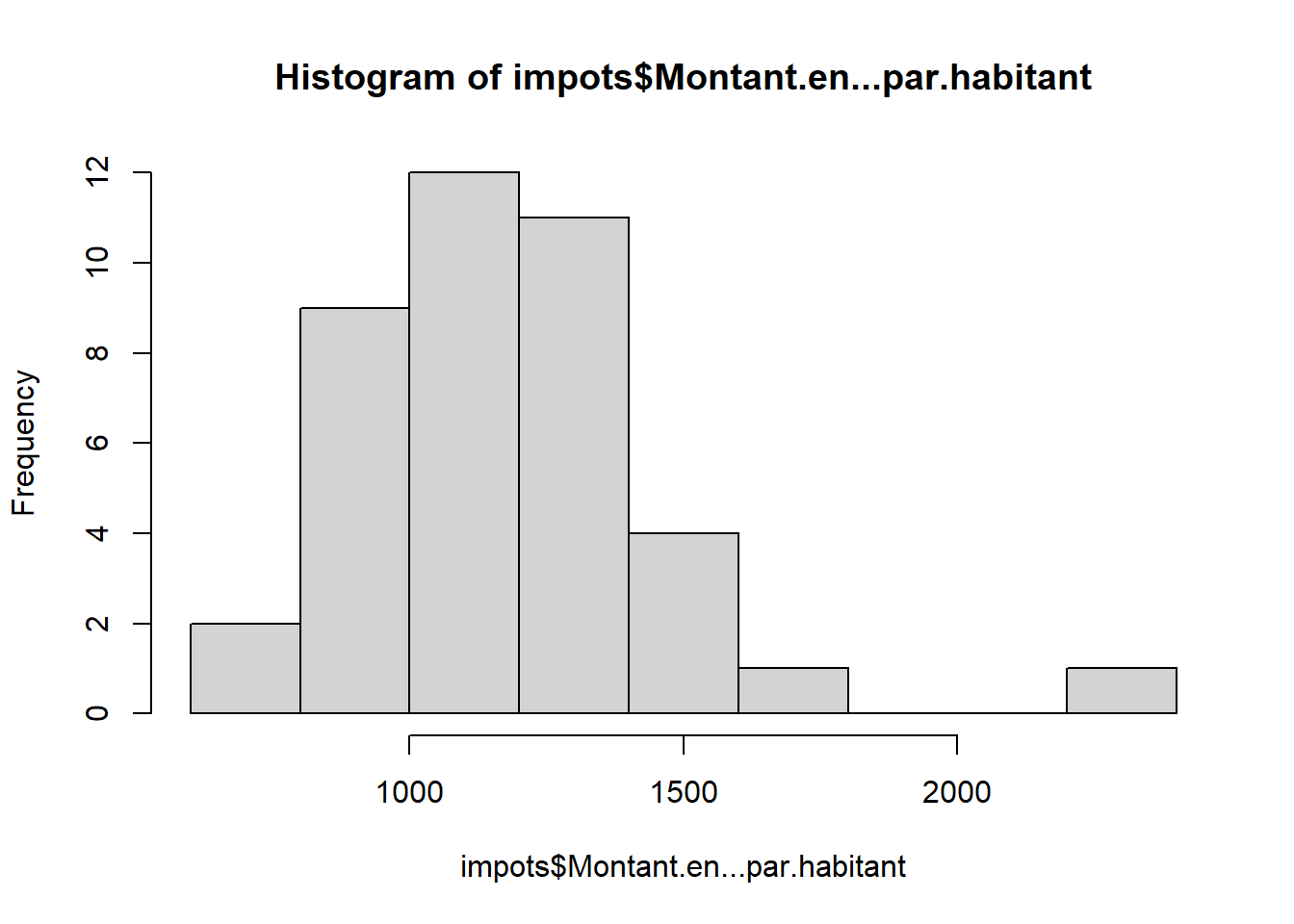
On recherche des bornes permettant d’avoir un nuage de points “cohérent”. Avec le tableur, on fait le graphique puis on ajuste avec le filtre au niveau de la donnée.
Le graphique se met automatiquement à jour

2.3.1.1 Filtre sous R
data <- read.csv("data/regression.csv", fileEncoding = "UTF-8")
sel <- data [(data$fraisPersonnel>600 & data$fraisPersonnel<1400) ,]
par(mfrow = c(1,2))
plot(data$fraisPersonnel, data$impots)
plot(sel$fraisPersonnel, sel$impots)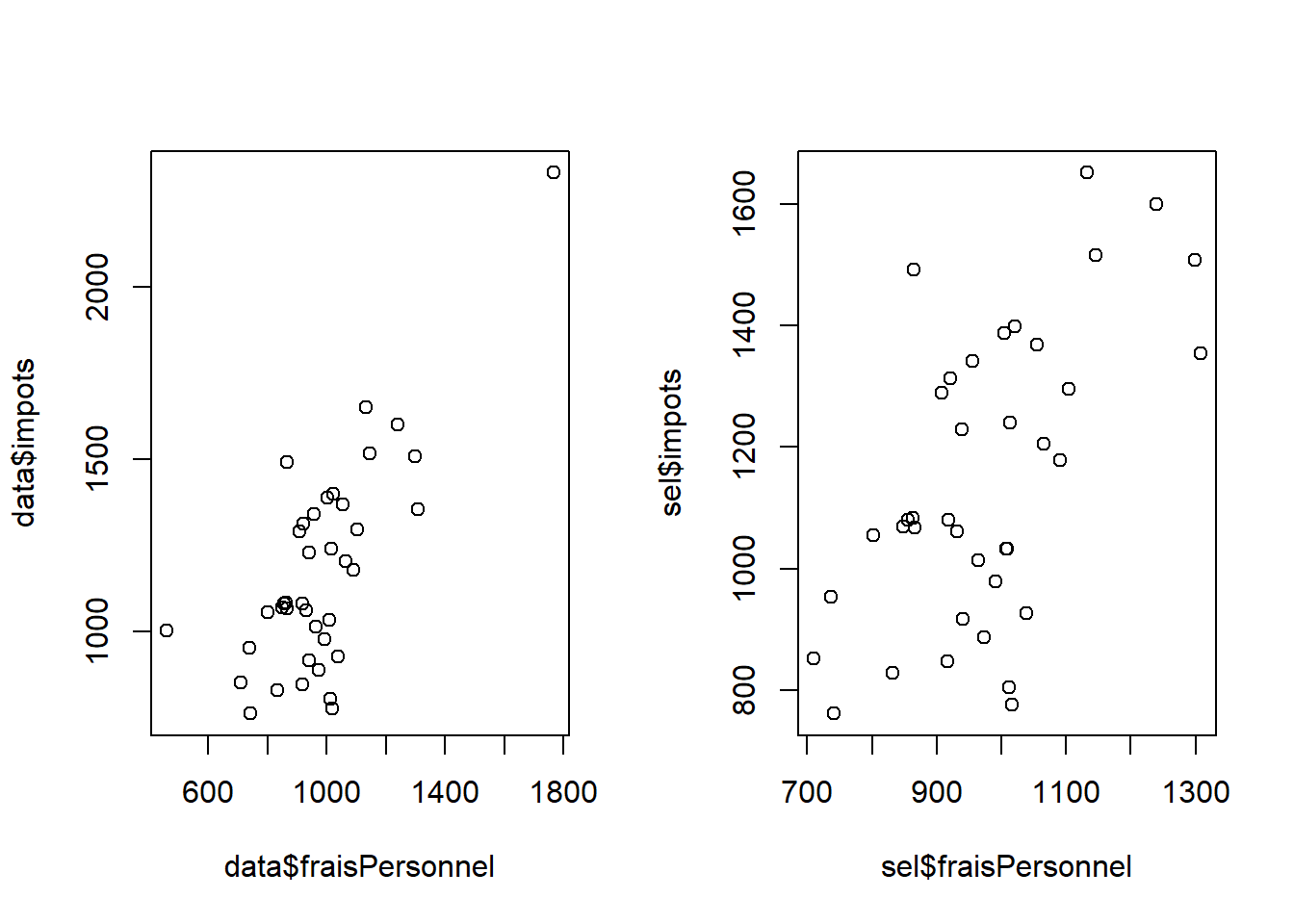
Désormais, on travaille sur la sélection et la totalité de la série pour vérifier que la restriction des bornes est utile.
3 Droite de régression
La droite de régression minimise la somme des carrés des distances verticales entre chacun des points du nuage et la droite recherchée.
Pour une droite aX+b
a (la pente) = covariance / variance X
b (ordonnée de l’origine) = moyenne de Y - a * moyenne de X
 La distance MP doit être minimale
d’où le terme droite des moindres carrées
La distance MP doit être minimale
d’où le terme droite des moindres carrées
3.0.1 Correction exercice droite de régression
3.0.1.1 Analyse : le message est passé

3.0.1.2 Vocabulaire
Les variables

 Hypothèse nulle
Hypothèse nulle

3.0.1.3 Le graphique
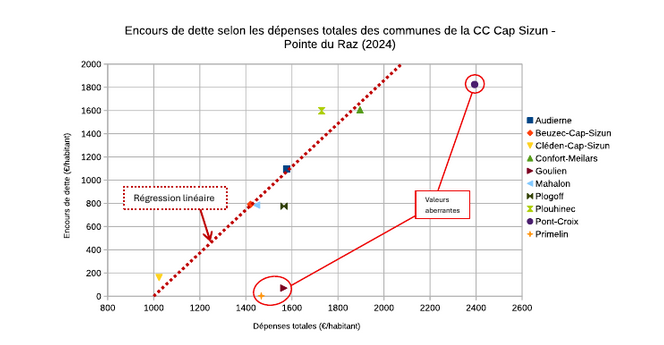
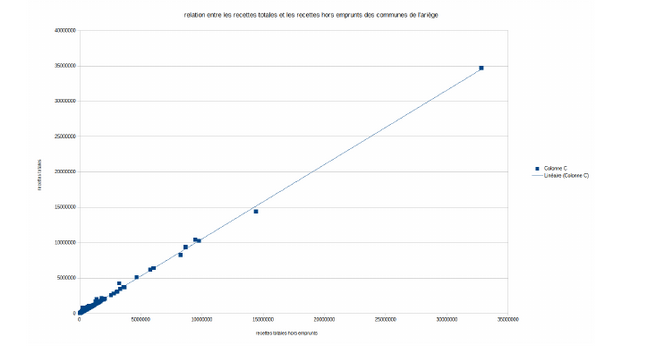
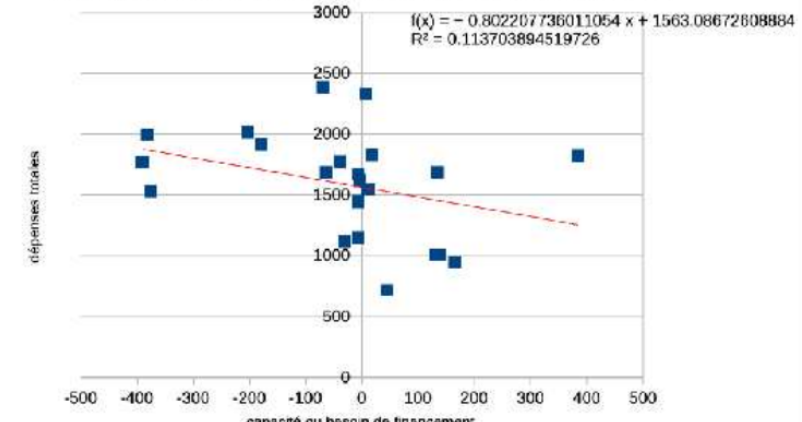
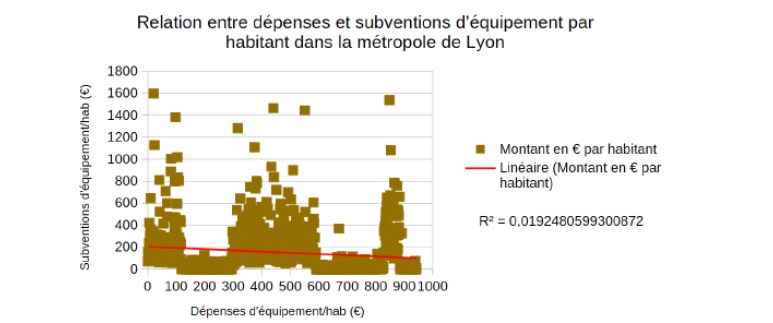
3.0.2 Droite de régression sous R
par(mfrow = c(2,1))
plot(data$fraisPersonnel, data$impots, pch=20)
# modèle de régression
lm <- lm(data$impots~data$fraisPersonnel)
abline(lm, lty =2, lwd = 1, col = "red")
text( data$fraisPersonnel, data$impots,labels = as.character(row.names(sel))
, cex=0.6, pos = 2)
# Pour la sélection
plot(sel$fraisPersonnel, sel$impots, pch=20)
# modèle de régression
lm <- lm(sel$impots~sel$fraisPersonnel)
abline(lm, lty =2, lwd = 1, col = "red")
text( sel$fraisPersonnel, sel$impots,labels = as.character(row.names(sel))
, cex=0.6, pos = 1, pch = 19)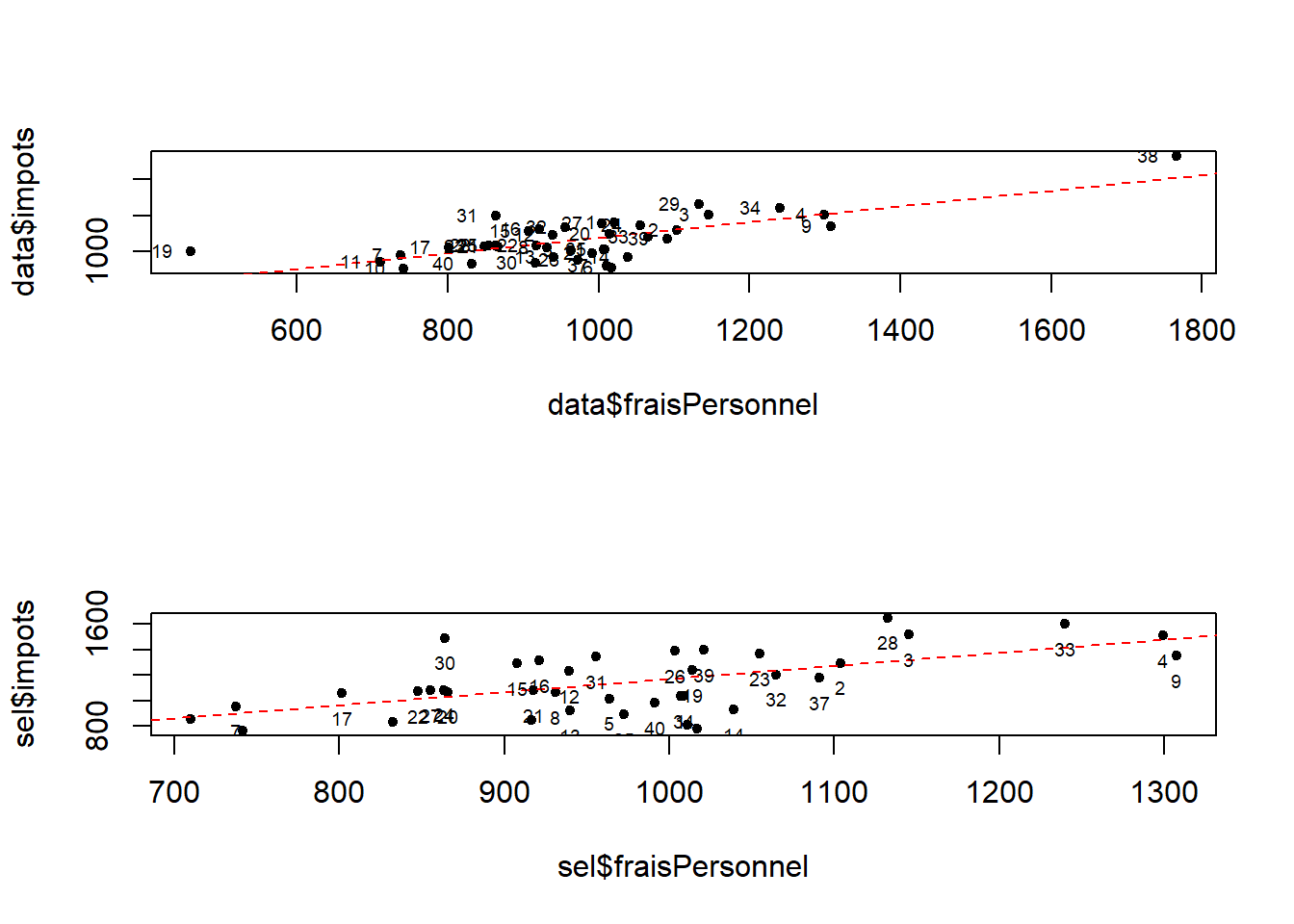
3.0.3 Dans Calc
Dans Calc, cliquer sur les points et insérer courbe de tendance (Trouver comment afficher l’équation de la droite.)
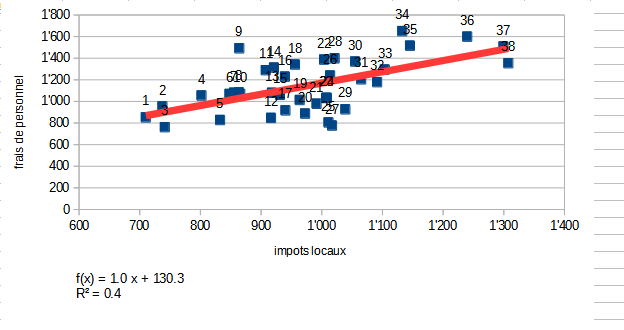
Visuellement, on voit bien qu’il existe un lien entre les deux variables, mais il y a beaucoup de points éparses (les résidus)
Il s’agit maintenant de mesurer précisemment l’intensité du lien à l’aide de calculs.
4 Coefficient de correlation
Autrement dit, le coefficient de Bravais-Pearson (1896). Pearson propose une formule mathématique pour la notion de corrélation.
Savoir-faire tableur : utiliser les noms pour les colonnes
4.0.1 Premier temps
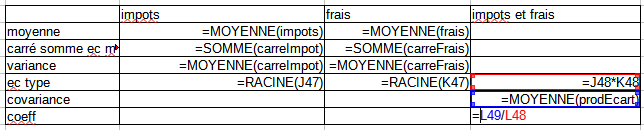
On rajoute des colonnes pour chaque variable :
écart à la moyenne
carré ( = distance plutôt que différence)
et pour les deux variables
- produit des écarts (pour étudier le rapport entre 2 variables, techniquement on utilise une division ou une multiplication)
4.0.2 Deuxième temps
Dans un nouveau tableau, pour chaque variable
moyenne
carré de la somme des écarts à la moyenne
Variance
Ecart type
puis covariance (produit des écarts / nb de valeurs)
et coeff (cov / produit des écarts types)

4.0.3 Interprétation
Le coefficient évolue de -1 à +1
Si r = 0, les variables ne sont pas corrélées.
Dans les autres cas, les variables sont corrélées négativement ou positivement.
plus la variable est proche de 1, plus l’intensité de la relation entre les deux variables est forte.
Dans notre exemple, lien assez fort
## fraisPersonnel impots
## fraisPersonnel 1.0000000 0.7291613
## impots 0.7291613 1.0000000## fraisPersonnel impots
## fraisPersonnel 1.0000000 0.5954511
## impots 0.5954511 1.0000000Le coefficient est plus fort si les deux valeurs extrêmes, Rosny et Tremblay sont conservées.
5 Coefficient de détermination
Au niveau mathématiques, c’est le carré du coefficient de corrélation linéaire
Mais c’est surtout :
Le rapport entre
- la variation de Y expliquée par le modèle
et
- la variation totale de Y
## fraisPersonnel impots
## fraisPersonnel 1.000000 0.354562
## impots 0.354562 1.000000Les frais du personnel explique 35 % du montant des impôts dans le meilleur des cas.
Les 75 % restant sont liés à d’autres facteurs.
6 Etude des résidus
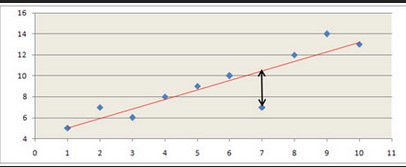
Identifiez graphiquement 2 points isolés de la droite de régression.
Dans notre exemple, ce sont les ville 28 et 30
## ville impots fraisPersonnel
## 31 Rosny-sous-Bois 1341.4859 955.9468
## 6 Clichy-sous-Bois 776.6742 1017.0168A Rosny sous Bois, les frais de personnel sont bas mais les impôt sont élévés. A Clichy sous Bois, les frais de personnel sont élévés mais les impots sont bas.
7 Cartographie des résidus
library(sf)
communes <- st_read("data/communes93.geojson")
communes <- communes [!is.na(communes$ref.INSEE), c("name", "ref.INSEE")]residus <- lm$residuals
hist(residus)
sel <- cbind(sel, residus)
# on calcule les résidus
jointure <- merge(communes, sel, by.x = "name", by.y = "ville")
summary(jointure$residus)library(mapsf)
png("img/residusCarte.png")
mf_map(jointure, var = "residus", type="choro", breaks = c(-500, -250,0,250,500), pal = cm.colors(4), border = NA, leg_pos = c(2.31589950651953, 48.8793057936166) )
mf_label(communes, var = "name", overlap = FALSE, col= "wheat4", cex = 0.8)
mf_layout("Frais de personnel et impôts : étude des résidus", credits = "OFGL, 2024")
dev.off()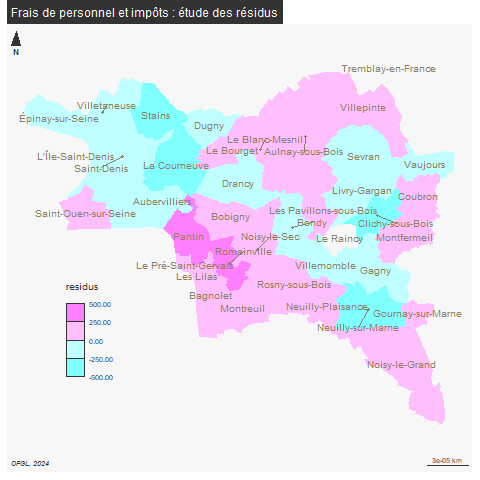
Tremblay et Rosny sous Bois sont écartées, elles représentaient des extrêmes.
Les villes dans les teintes les plus foncées s’éloignent le plus du modèle.
L5GEABIM Analyses bivariées et multivariées